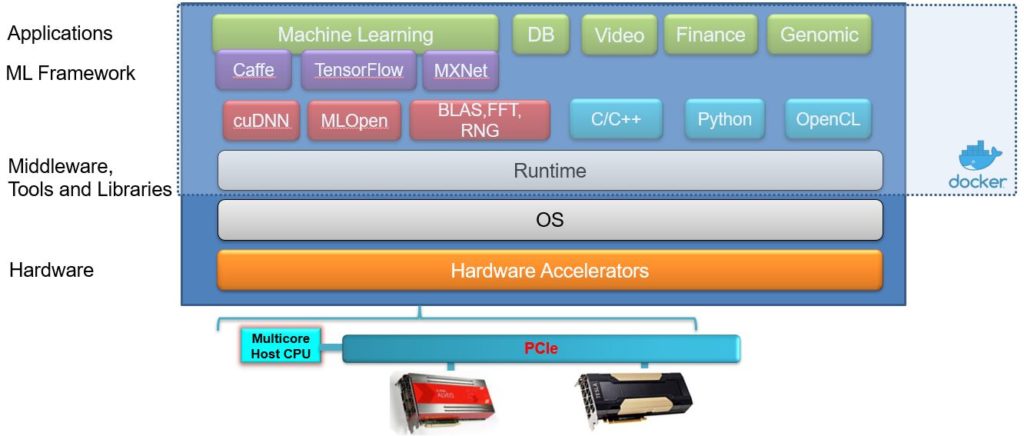
Le groupe FPGA/GPU prend en charge trois des cadres d’apprentissage en profondeur les plus couramment utilisés, à savoir TensorFlow, Caffe et MXNet. Ces cadres fournissent une couche d’abstraction de haut niveau pour la spécification de l’architecture d’apprentissage en profondeur, la formation de modèles, le réglage, les tests et la validation. La pile logicielle comprend également plusieurs bibliothèques spécifiques à chaque fournisseur d’apprentissage de machines qui fournissent des fonctions informatiques dédiées adaptées à une architecture matérielle spécifique, fournissant le meilleur rendement/puissance possible.