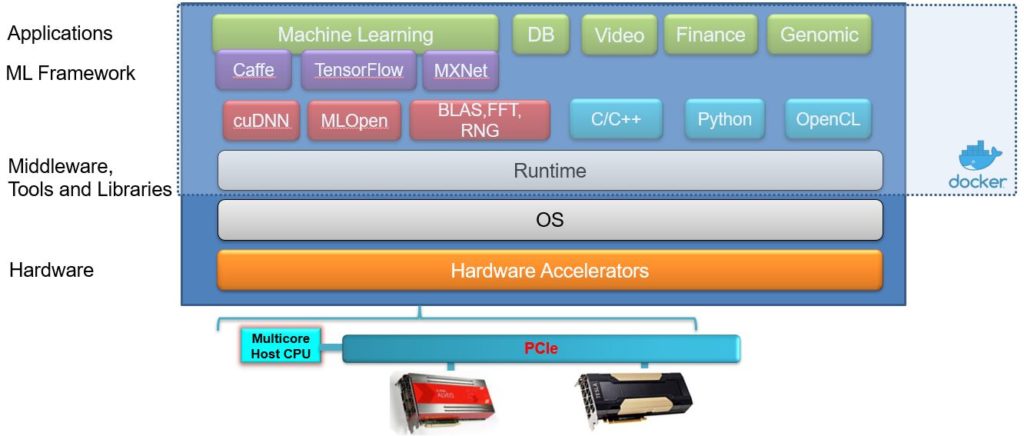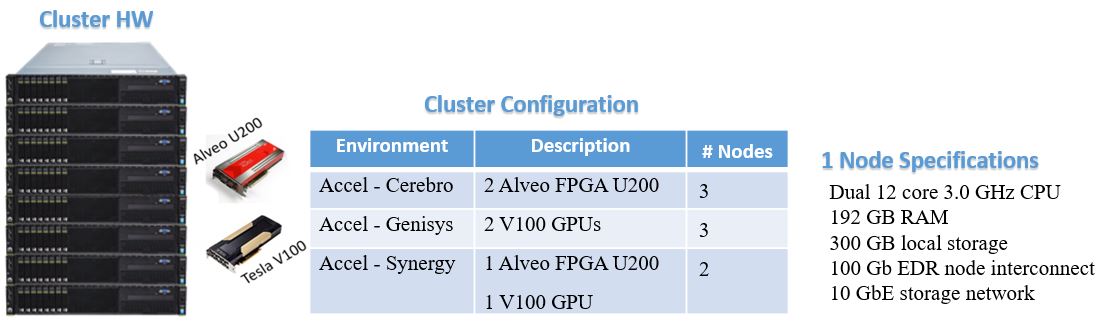
The FPGA/GPU cluster supports three the most commonly used deep learning frameworks, namely, TensorFlow, Caffe and MXNet. These frameworks provide a high-level abstraction layer for deep learning architecture specification, model training, tuning, testing, and validation. The software stack also includes various machine learning vendor-specific libraries that provide dedicated computing functions tuned for specific hardware architecture, delivering the best possible performance/power figure.